AI tools for text to speech with celebrity voices
Related Tools:
KlipLab
KlipLab is an AI-powered platform that enables users to create voiceovers and lip-synced videos using the voices of celebrities, public figures, and fictional characters. With a variety of high-quality voices to choose from, realistic lip sync generation, and the ability to customize video and audio, KlipLab offers a seamless experience for content creators and social media enthusiasts. The application provides different pricing plans to cater to varying needs and preferences, ensuring flexibility and accessibility for users. KlipLab prioritizes security and user satisfaction, utilizing Stripe for payment processing and offering responsive customer support.
Voices AI
Voices AI is an AI voice generator and celebrity voice changer application that allows users to craft audio using the voices of celebrities, politicians, and movie characters. It offers features such as turning text into speech, chatting with AI characters, emotional speech with speech-to-speech capabilities, voice cloning, generating AI songs, and a vast library of hyper-realistic AI voices. The application ensures privacy of voice recordings and updates its voice library regularly to include trending and popular voices. Voices AI stands out from other voice generation tools with its focus on continuous innovation, user experience, and audio quality.
Voxdazz
Voxdazz is a celebrity AI voice generator website that allows users to select a celebrity template, input text, and generate a video with lifelike voices. With famous characters like Donald Trump, Joe Biden, and more, Voxdazz offers a fun and entertaining way to bring words to life through AI-generated voices. The service provides realistic voice cloning technology for creating humorous content, skits, and parodies with friends and family.
Audyo
Audyo is an AI tool that allows users to create human-quality AI voices easily by simply typing text. With over 100 voices to choose from, users can select speakers in various languages, accents, and even celebrity impersonators. The tool enables users to edit words, not waveforms, and export audio for use in videos, podcasts, presentations, and more. Audyo also offers features like creating conversations, mixing and matching languages, customizing pronunciations, and utilizing an AI assistant for script tweaking. Users can enjoy 15 minutes of audio generation with a free account and earn additional time by inviting friends. Audyo empowers creators to unleash their imagination and enhance their content with lifelike AI voices.
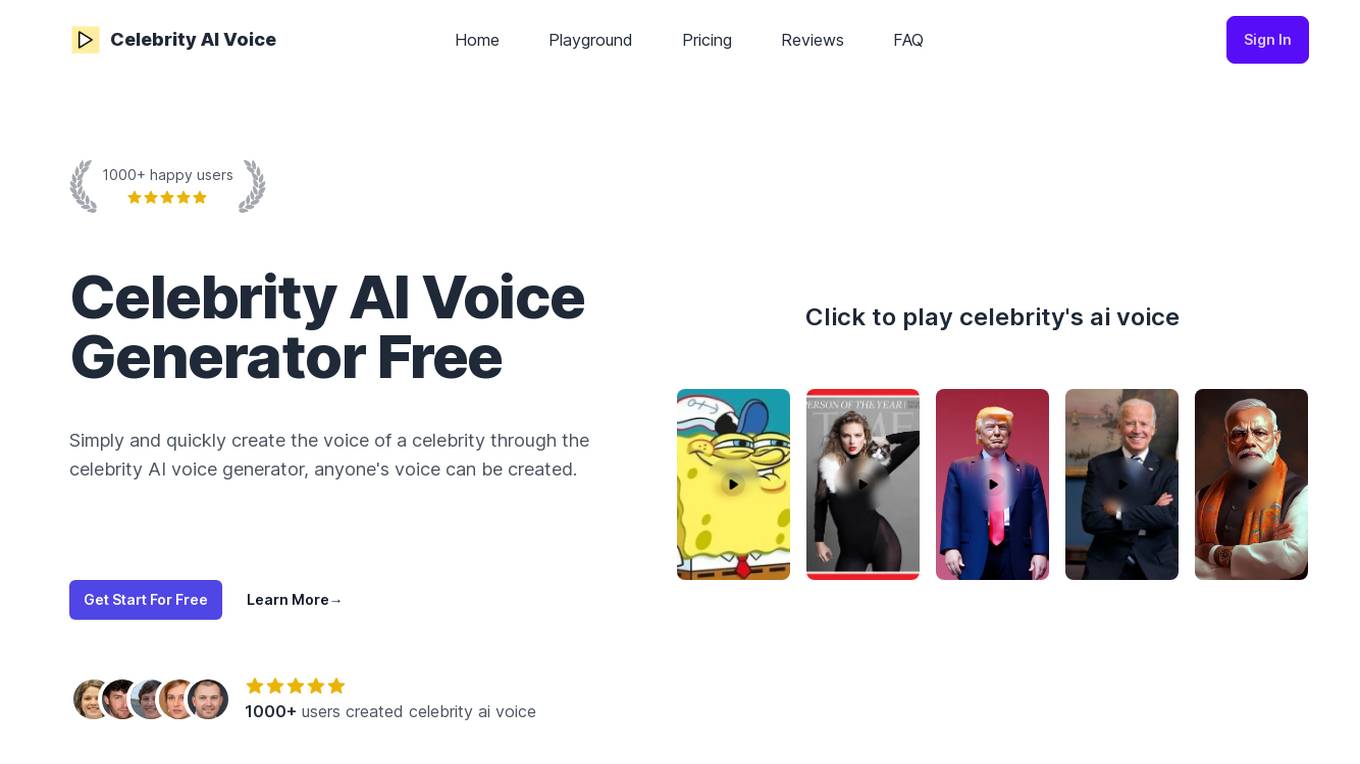
Celebrity AI Voice Generator
Celebrity AI Voice Generator is a free online tool that allows you to create realistic AI-generated voices of celebrities. With just a short audio clip of the person you want to replicate, you can generate voices that sound incredibly real. The tool is easy to use and offers a variety of features, including the ability to control voice styles, emotions, and accents. You can also use the tool to generate voices in different languages. Celebrity AI Voice Generator is a powerful tool that can be used for a variety of purposes, including creating voiceovers, dubbing videos, and developing video games.
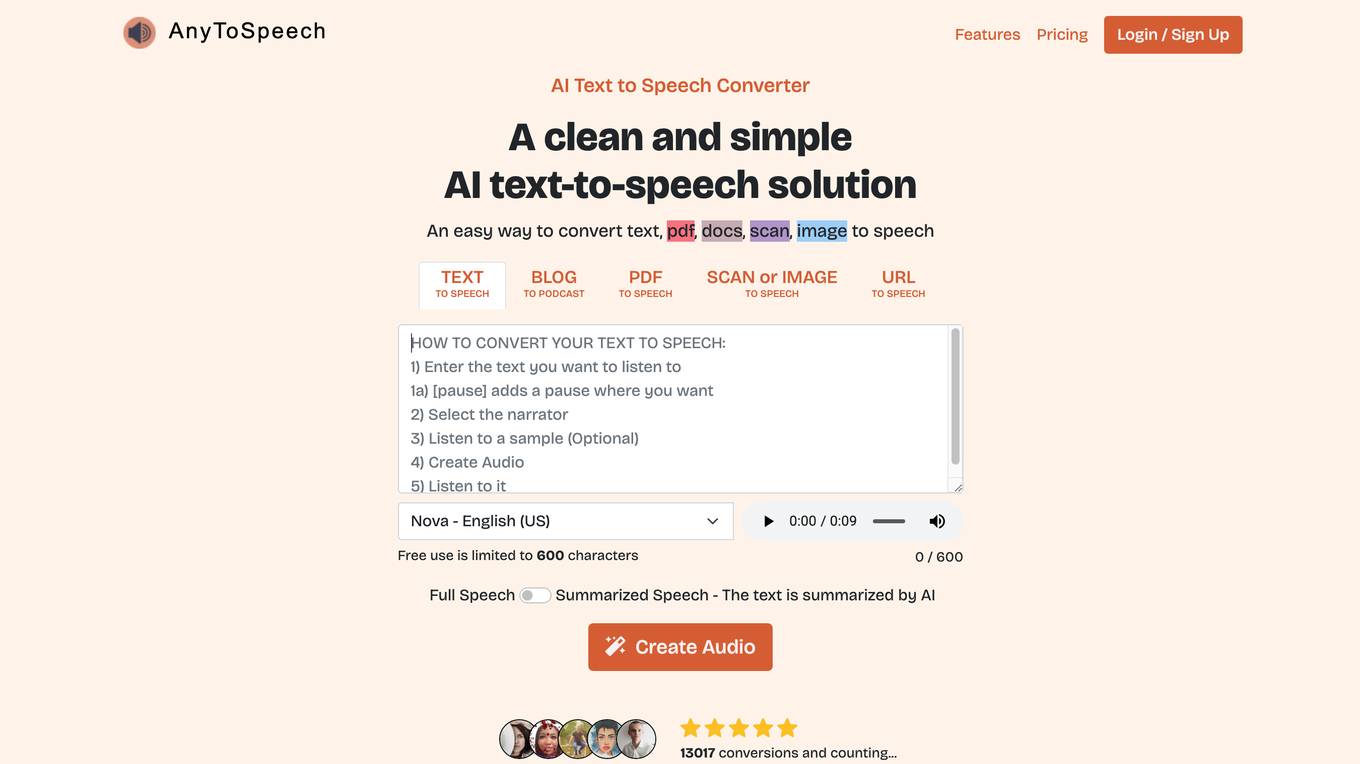
AnyToSpeech
AnyToSpeech is an AI text-to-speech and PDF to Audiobook solution that offers a clean and simple way to convert text, PDFs, documents, scans, and images to speech. It provides a variety of realistic voices in multiple languages for users to choose from. The platform also allows users to convert URLs to speech and offers a library to save and access their generated audio files at any time.
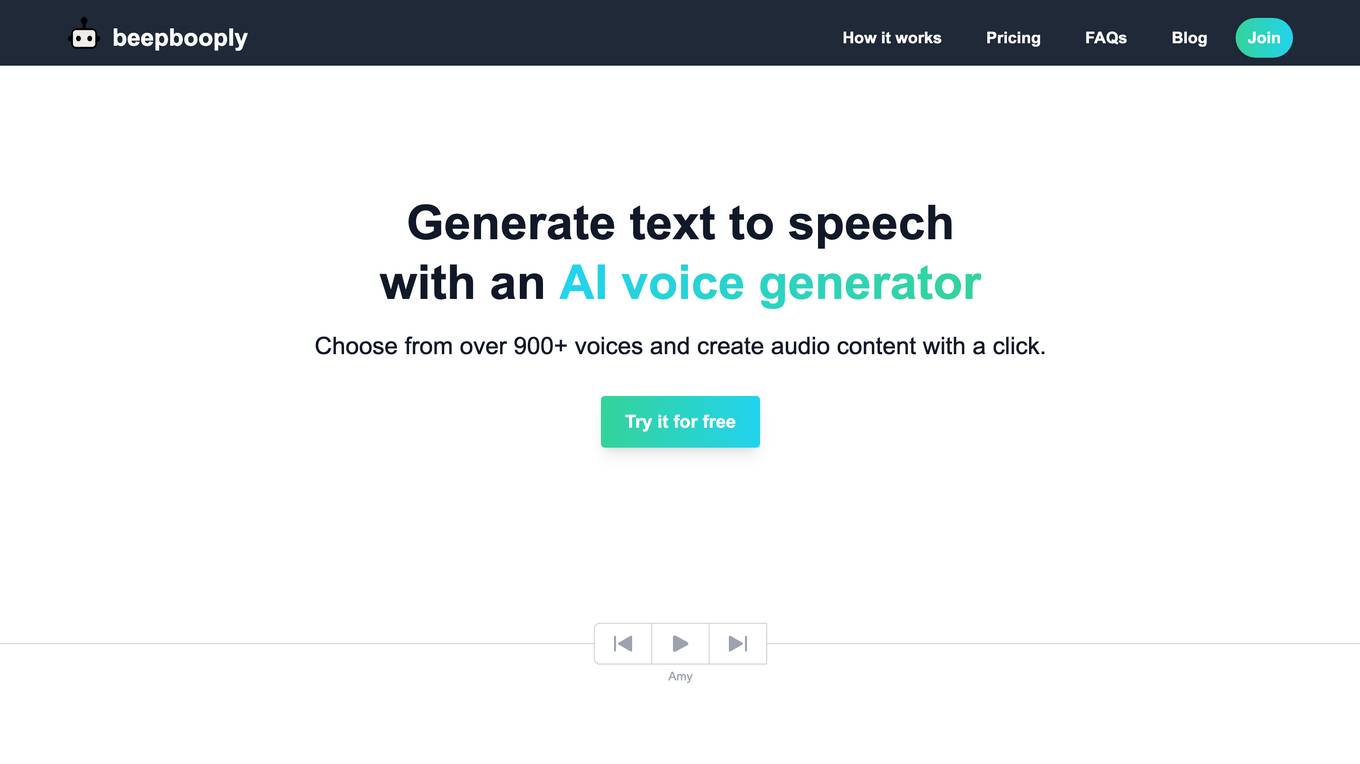
Beepbooply
Beepbooply is a text-to-speech tool that uses artificial intelligence to generate realistic and natural-sounding speech. With over 900 voices to choose from, you can create audio content for any purpose, including videos, podcasts, and customer service. Beepbooply is easy to use and affordable, making it a great option for anyone who needs to create high-quality audio content.
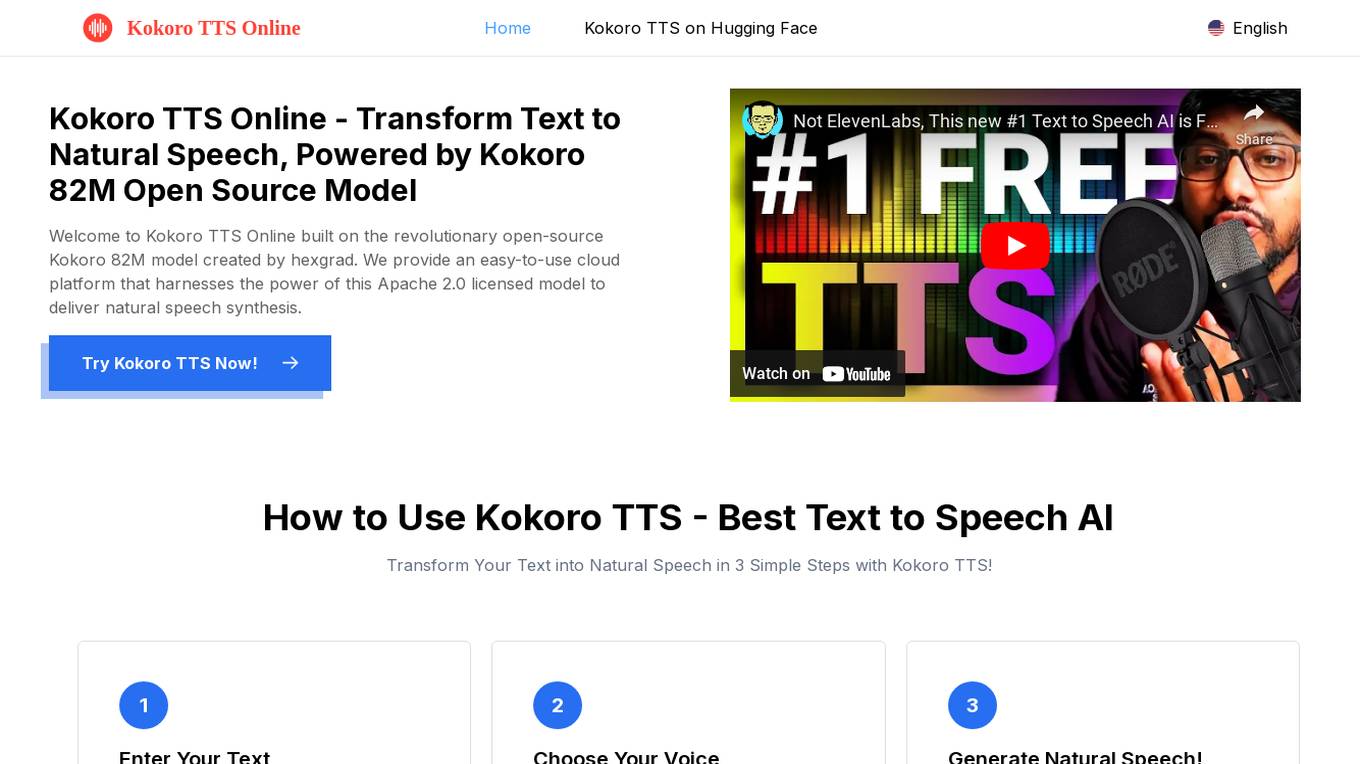
Kokoro TTS Online
Kokoro TTS Online is a professional cloud service powered by the Kokoro 82M open-source model. It offers text-to-speech conversion with natural speech synthesis using advanced AI technology. Users can transform text into natural-sounding speech in seconds, choose from multiple voices, and experience superior audio quality. Kokoro TTS is user-friendly, supports American and British English, and is suitable for various applications such as creating voiceovers, podcasts, and learning materials.
DubSmart
DubSmart is an AI-powered platform that offers advanced video dubbing and voice cloning services. It allows users to transform text into lifelike speech, dub videos with voice cloning technology, and generate subtitles for audio or video content. With a user-friendly interface, DubSmart enables users to create unique voices, edit projects, and download finished projects in various formats. The platform supports 33 languages for AI dubbing and 60+ languages for speech-to-text conversion. DubSmart caters to small creators, YouTubers, and companies looking to enhance their audiovisual content with personalized voices and multilingual capabilities.

Wavflow
Wavflow is an AI text-to-speech tool that converts written text into natural-sounding speech. It utilizes advanced artificial intelligence algorithms to generate high-quality audio output, making it ideal for various applications such as creating podcasts, voiceovers, audiobooks, and more. With a user-friendly interface and customizable options, Wavflow offers a seamless experience for users looking to transform text into speech effortlessly.
Nemesys Labs
Nemesys Labs is a free AI-powered text-to-speech platform that utilizes artificial intelligence technology to convert written text into spoken words. Users can easily generate high-quality audio files from any text input, making it a valuable tool for content creators, educators, and individuals seeking accessible content. The platform offers a user-friendly interface and a range of customization options to tailor the voice, tone, and speed of the generated speech. Nemesys Labs aims to enhance communication and accessibility by providing a seamless text-to-speech solution for various applications.
Lovevoice AI Voice Generator
Lovevoice is an AI Voice Generator that transforms text into natural-sounding speech using AI technology. It offers over 70 languages and nearly 300 AI voices, customizable voice settings, file transcription support, and MP3 download capabilities. Lovevoice's advanced AI ensures generated voiceovers are human-like, making it ideal for various applications such as videos, podcasts, audiobooks, and personalized audio messages. Users can quickly convert text into high-quality audio files with multilingual global support.
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.
AI Voice Studio
AI Voice Studio is an innovative online tool that allows users to convert text into lifelike speech using advanced AI technology. With AI Voice Studio, users can easily create high-quality voiceovers for various purposes such as videos, podcasts, and presentations. The tool offers a user-friendly interface and a wide range of customization options to tailor the voice output to specific needs. Whether you are a content creator, marketer, or educator, AI Voice Studio provides a convenient and efficient solution for generating natural-sounding voice content.
Vocalx
Vocalx is an AI-powered online tool that converts text into natural-sounding speech. It utilizes advanced speech synthesis technology to generate lifelike voices for various applications. Users can easily create audio content from written text, making it ideal for content creators, educators, and businesses looking to enhance their multimedia offerings. With Vocalx, you can customize the voice, tone, and speed of the generated speech to suit your needs. The tool supports multiple languages and accents, providing a versatile solution for voiceover projects, audiobooks, podcasts, and more.

ttsMP3.com
ttsMP3.com is a free Text-To-Speech and Text-to-MP3 tool that allows users to easily convert US English text into professional speech for various purposes such as e-learning, presentations, YouTube videos, and website accessibility. The tool offers a wide range of voices in different languages and accents, including regular and AI voices. Users can download the generated speech as MP3 files, and customize speech with features like breaks, emphasis, speed adjustments, pitch variations, whispers, and conversations. Supported voice languages include Arabic, English, Portuguese, Spanish, Chinese, Danish, Dutch, French, German, Icelandic, Indian, Italian, Japanese, Korean, Mexican, Norwegian, Polish, Romanian, Russian, Swedish, Turkish, and Welsh.
ElevenLabs
ElevenLabs is an AI audio platform that offers Text to Speech, AI Voice Generator, and more. It provides high-quality, human-like speech in 32 languages, suitable for audiobooks, video voiceovers, commercials, and various other applications. The platform also includes features like Voice Changer, Dubbing, Voice Cloning, and Conversational AI tools. ElevenLabs aims to bridge language gaps, enhance storytelling, and make digital interactions more human through its AI audio solutions.
Zonos TTS
Zonos TTS is an advanced multilingual text-to-speech tool that utilizes high-quality AI technology to deliver natural and expressive voice generation. With features like zero-shot voice cloning, multilingual support, and emotion control, Zonos TTS offers users the ability to create lifelike speech with customizable settings. The tool is suitable for various applications, from content creation to virtual assistants, audiobooks, gaming, e-learning, and more. Zonos TTS provides fast real-time processing and a user-friendly interface for seamless speech synthesis.

AI Voice Generator
AI Voice Generator is a Telegram bot that converts text into audio using artificial intelligence. It offers a variety of neural voices, making it easy to create natural-sounding voiceovers. The bot is simple to use, and you can generate audio in seconds.
Video GPT
AI Video Maker. Generate videos for social media - YouTube, Instagram, TikTok and more! Free text to video & speech tool with AI Avatars, TTS, music, and stock footage.
Chat with GPT 4o ("Omni") Assistant
Try the new AI chat model: GPT 4o ("Omni") Assistant. It's faster and better than regular GPT. Plus it will incorporate speech-to-text, intelligence, and speech-to-text capabilities with extra low latency.
Speech Parody
Create speech transcript parodies. Copyright (C) 2023, Sourceduty - All Rights Reserved.


Text to DB Schema
Convert application descriptions to consumable DB schemas or create-table SQL statements
Text to Image
Text to Image .Expert in crafting Text prompts for Stability AI Image generation.
Text-to-Image
Custom text-entry images. Copyright (C) 2023, Sourceduty - All Rights Reserved.
Text to Video Maker
The Assistant helps you create high-quality video prompts by easily utilizing InVideo technology By Mr Sora
Text Playground
Best AI-powered Text Playground!! I am your go-to assistant for text-to other media conversions. Flawelessly convert any text to voice, image, or video!! I am here to help. Ask me anything!!
Malevich GPT - Emoji to Art 🤯 -> 🎨
Convert emotions and feelings to evocative abstract art. Share you daily mood with text or emoji and I help you to create masterpiece .
Narrify AI
Narrify AI is an AI-powered application that transforms your videos by adding sports commentary to them. With Narrify AI, users can upload any video file up to 45 seconds in length and enhance it with personalized commentary, highlighting names and key words. The application allows users to create engaging and fun narrated videos to share with friends and family. Narrify AI is a user-friendly tool that adds a unique touch to your videos, making them more entertaining and memorable.